
글에서 쓰이는 모든 코드는 제가 쓴 것이 아닙니다. 동계캠프를 진행하는 동안의 수업 자료입니다.
러시아 장기에서 머리가 깨질뻔하게 했던 큐러닝... 큐함수가 뭔지... 엡실론이 뭔지 ㅠ_ㅠ 정말 어려웠지만, 4x4 오델로를 만들며 이해가 조금은 더 돼서 좋았던 녀석이다.
내가 이해한 Q-Learning은 상태-> 행동에 기반한 보상이 주어지는 알고리즘이다. DP는 상태에 따른 보상의 가치 함수였다면, Q함수는 상태에 따른 행동에 따른 보상을 가진 함수이다.
Q-Learning AI는 이런 기능으로 세분화해 개발했다.
- 가치함수 초기화
- 학습
- 엡실론 그리디 정책에 의한 첫번째 행동 선택
- 최적의 다음 상태와 보상 구하기
- 가치 함수 업데이트
- 에피소드 반복 학습
이렇게 개발했다. 물론 내가 아닌 선생님이... 지금 코드를 세분화했어도 이게 뭔지, 시원한 이해를 못한다...
1. 가치함수 초기화
Dictionary<int, Dictionary<int, float>> actionValueFunction;상태에 따른 행동, 그 행동에 따른 보상을 저장해줘야하기 때문에 두 개의 Dictionary를 썼다.
(1) 각 행동을 통해 전이한 상태를 각각의 복합 데이터에 저장한다.
List<int> childStateList = new List<int>();
for (int i = GameParameters.ActionMinIndex; i <= GameParameters.ActionMaxIndex; i++) // 모든 행동에 대해 루프를 수행
{
if (processingGameState.IsValidMove(i)) // 이 행동이 올바른 행동이면
{
GameState nextState = processingGameState.GetNextState(i); // 행동을 통해 전이해 간 다음 상태 구성
childStateList.Add(nextState.BoardStateKey); // 자식 상태 임시 후보 리스트에 추가
actionValues.Add(i, 0.0f); // 가치 함수값을 0으로 초기화 한후 dictionary에 추가
}
}
if (childStateList.Count == 0) // 만일 후보 리스트에 포함된 상태가 없으면
{
GameState nextState = processingGameState.GetNextState(0); // Pass 로 턴만 바뀐 상태 생성
childStateList.Add(nextState.BoardStateKey); // 임시 후보 리스트에 추가
actionValues.Add(0, 0.0f); // Pass 행동
}
코드가 너무 길어 잘랐지만, 이는 각 상태에 대한 행동이다. Q함수가 상태->행동에 기반한 보상을 반환하는 함수이므로!
여기서 구한 actionValues는 각 상태를 키 값으로 한 Value가 된다!
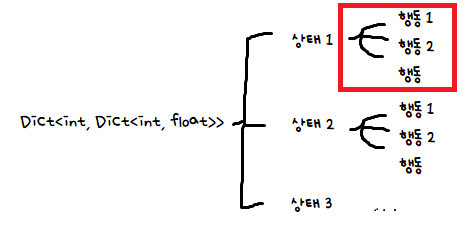
이 부분을 채우고 있었던 것이다!
(2) 1을 각 상태에 따라 가치 함수 (Dict)에 넣어준다.
// 임시 후보 리스트의 상태 중 자식 상태 리스트에 포함되어 있지 않은 상태를 자식 상태 리스트에 추가
mergedChildStateList.AddRange(childStateList.Where(e => !mergedChildStateList.Contains(e)));
}
actionValueFunction.Add(gameBoardKey, actionValues); // 가치 함수에 추가
}
}
if (mergedChildStateList.Count == 0) // 자식 상태 리스트에 상태가 없으면
break; // 루프 종료
else
boardStateKeyList = new List<int>(mergedChildStateList); // 게임 상태 후보 리스트를 자식 상태로 치환하고 루프 지속
왜 코드를 이렇게 자른지 모르겠다... 큰 틀에서부터 보는 게 좋지만, 그러면 코드가 너무 길어져 나중에 다시봤을 때 이해하기 힘들 것 같아서 작은 로직부터 큰 로직으로 향했는데... 좋은 방법은 아닌 것 같다.
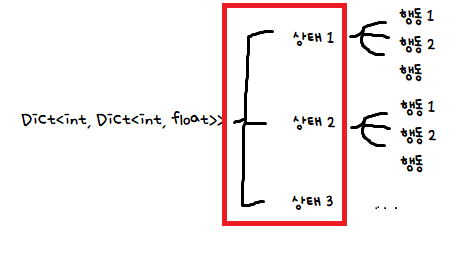
아무튼, 이 부분은 1에서 구한 Q함수를 큰 가치 함수에 넣어주는 작업이다.
그 과정에서 새로 생긴 상태들은 루프를 계속 돌아주고, 새로 생긴 상태가 없다면 루프를 종료해주며 가치 함수 초기화를 종료한다!
초기화된 가치 함수 반환하는 전체 코드
public static Dictionary<int, Dictionary<int, float>> CreateActionValueFunction()
{
// SARSA, Q 러닝에서 사용되는 행동 가치 함수를 초기화하는 함수
Dictionary<int, Dictionary<int, float>> actionValueFunction = new Dictionary<int, Dictionary<int, float>>();
GameState gameState = new GameState(); // 초기 게임 상태 생성
List<int> boardStateKeyList = new List<int>(); // 게임 상태 후보 리스트 선언
boardStateKeyList.Add(gameState.BoardStateKey); // 초기 상태 게임 상태키를 후보 리스트에 추가
while (true) // 루프 시작
{
List<int> mergedChildStateList = new List<int>();
foreach (int gameBoardKey in boardStateKeyList) // 게임 상태 후보 리스트에 있는 상태들에 대해
{
if (!actionValueFunction.ContainsKey(gameBoardKey)) // 가치 함수에 아직 포함되지 않았으면
{
Dictionary<int, float> actionValues = new Dictionary<int, float>();
GameState processingGameState = new GameState(gameBoardKey); // 게임 상태 생성
if (!processingGameState.IsFinalState()) // 게임 종료 상태가 아니면
{
List<int> childStateList = new List<int>();
for (int i = GameParameters.ActionMinIndex; i <= GameParameters.ActionMaxIndex; i++) // 모든 행동에 대해 루프를 수행
{
if (processingGameState.IsValidMove(i)) // 이 행동이 올바른 행동이면
{
GameState nextState = processingGameState.GetNextState(i); // 행동을 통해 전이해 간 다음 상태 구성
childStateList.Add(nextState.BoardStateKey); // 자식 상태 임시 후보 리스트에 추가
actionValues.Add(i, 0.0f); // 가치 함수값을 0으로 초기화 한후 dictionary에 추가
}
}
if (childStateList.Count == 0) // 만일 후보 리스트에 포함된 상태가 없으면
{
GameState nextState = processingGameState.GetNextState(0); // Pass 로 턴만 바뀐 상태 생성
childStateList.Add(nextState.BoardStateKey); // 임시 후보 리스트에 추가
actionValues.Add(0, 0.0f); // Pass 행동
}
// 임시 후보 리스트의 상태 중 자식 상태 리스트에 포함되어 있지 않은 상태를 자식 상태 리스트에 추가
mergedChildStateList.AddRange(childStateList.Where(e => !mergedChildStateList.Contains(e)));
}
actionValueFunction.Add(gameBoardKey, actionValues); // 가치 함수에 추가
}
}
if (mergedChildStateList.Count == 0) // 자식 상태 리스트에 상태가 없으면
break; // 루프 종료
else
boardStateKeyList = new List<int>(mergedChildStateList); // 게임 상태 후보 리스트를 자식 상태로 치환하고 루프 지속
}
return actionValueFunction;
}
2. 학습!
(1) 상태에 대한 행동을 입실론 그리디 정책을 통해 구한다.
E-Greedy Algorithm(입실론 그리디 알고리즘)이란?
1. E-Greedy Algorithm(입실론 그리디 알고리즘)이란? [ Greedy Algorithm(그리디 알고리즘) ] Greedy Algorithm은 미래를 생각하지 않고 각 단계에서 가장 최선의 선택을 하는 기법이다. 즉, 각 단계에서 최선의
mangkyu.tistory.com
배울 당시에는 AI에 랜덤 확률을 쓰는 것에 대한 혼동과 혼란이 왔었지만, 이 글을 보고 입실론 그리디 알고리즘을 쓰는 이유를 알게 되었다.
항상 순간의 최적해를 선택해 탐험이 부족한 그리디 알고리즘을 개선시켜, 일정 확률로 탐험을 하도록 한 알고리즘이다!
행동 구하기
// Epsilon 탐욕 정책으로 첫번째 행동 선택
int firstAction = Utilities.GetEpsilonGreedyAction(firstState.NextTurn, ActionValueFunction[firstState.BoardStateKey]);
입실론 그리디 알고리즘
public static int GetEpsilonGreedyAction(int turn, Dictionary<int, float> actionValues)
{
float greedyActionValue = 0.0f;
float epsilon = 10;
if (actionValues.Count == 0)
return 0;
if (turn == 1)
greedyActionValue = actionValues.Select(e => e.Value).Max();
else if (turn == 2)
greedyActionValue = actionValues.Select(e => e.Value).Min();
int exploitRandom = random.Next(0, 100);
IEnumerable<int> actionCandidates = null;
// 10% 확률로 그리디 값이 아닌 것들 또한 선택
if (exploitRandom < epsilon)
{
actionCandidates = actionValues.Where(e => e.Value != greedyActionValue).Select(e => e.Key);
}
// null이거나 그리디 최적해 외 카운트가 0이라면
if (actionCandidates == null || actionCandidates.Count() == 0)
actionCandidates = actionValues.Where(e => e.Value == greedyActionValue).Select(e => e.Key);
return actionCandidates.ElementAt(random.Next(0, actionCandidates.Count()));
}
(2) 다음 상태에 대한 보상을 계산한다.
입실론 그리디 알고리즘을 통해 얻은 행동으로 다음 상태를 만들어준다.
// 선택된 행동을 통해 전이해 간 두번째 상태 생성
GameState secondState = firstState.GetNextState(firstAction);
// 두번째 상태에 대한 보상 계산
float reward = secondState.GetReward();(3) 가치 함수를 업데이트한다.
// 첫번째 상태, 행동에 대한 가치 함수값
float firstStateActionValue = ActionValueFunction[firstState.BoardStateKey][firstAction];
// 두번째 상태에 대한 가치 함수값
float secondStateActionValue = Utilities.GetGreedyActionValue(secondState.NextTurn, ActionValueFunction[secondState.BoardStateKey]);
// 가치 함수 업데이트
float updatedActionValue = firstStateActionValue + UpdateStep * (reward + DiscountFactor * secondStateActionValue - firstStateActionValue);
ActionValueFunction[firstState.BoardStateKey][firstAction] = updatedActionValue;사실 여긴 정말 이해를 못하겠다... 넌 도대체 어디서 나온 공식이니 ㅠ_ㅠ 수업을 들은 거야 만 거야!!!
선생님께 메일로 여쭤봐야겠다... 여쭤본 뒤 내용은 여기 올리겠다.
(4) 1~3까지 에피소드가 끝날 때까지 반복한다.
while (!episodeFinished)
{
// (1)~(3) 코드
if (secondState.IsFinalState() || ActionValueFunction[secondState.BoardStateKey].Count == 0) // 에피소드가 종료된 경우
{
episodeFinished = true;
episodeCount++;
}
else // 에피소드가 계속 진행되는 경우. 두번째 상태를 첫번째 상태로 재설정
{
firstState = secondState;
}
}
이렇게 생략을 하니 좋은 것 같다! 해당 에피소드의 게임이 끝나면, 에피소드가 종료된다.
(5) N개의 에피소드가 종료되면 학습이 끝난다.
if (episodeCount > 1000000) // 에피소드 100만개 처리 후 종료
{
keepUpdating = false;
}
이 모든 과정들은 여러 개의 에피소드를 거듭해가며, 강화 학습을 해가는 과정이다.
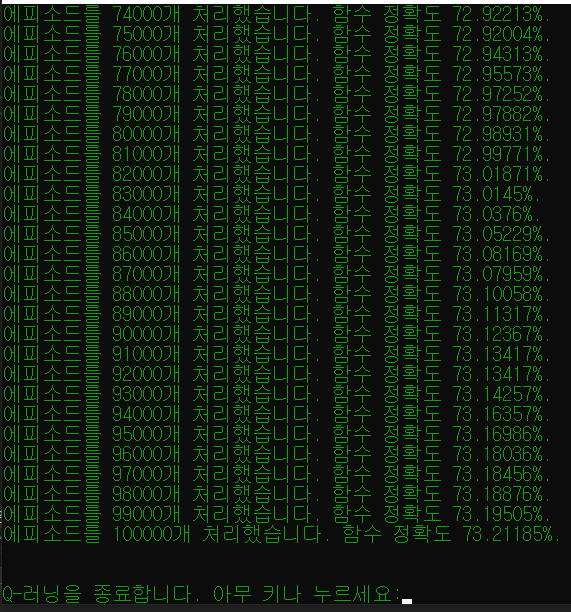
3. 게임
이렇게 강화학습을 한 Q-Learning AI는 어떻게 행동을 구할까?
public int GetNextMove(int boardStateKey)
{
// 주어진 게임 상태에 대한 행동 결정
GameState gameState = new GameState(boardStateKey);
return Utilities.GetGreedyAction(gameState.NextTurn, ActionValueFunction[boardStateKey]);
}
GetGreedyAction에 현재 누구 턴인지와 Q함수를 보낸다!
GetGreedyAction 함수에 가보자.
public static int GetGreedyAction(int turn, Dictionary<int, float> actionValues)
{
IEnumerable<int> actionCandidates = GetGreedyActionCandidate(turn, actionValues);
if (actionCandidates.Count() == 0)
return 0;
return actionCandidates.ElementAt(random.Next(0, actionCandidates.Count()));
}
행동 후보들을 반환하는 함수를 호출한다! 그 중 하나를 랜덤 액션으로 준다. 후보들은 어떤 기준으로 정해지는지 보자.
public static IEnumerable<int> GetGreedyActionCandidate(int turn, Dictionary<int, float> actionValues)
{
float greedyActionValue = 0.0f;
if (turn == 1)
{
greedyActionValue = actionValues.Select(e => e.Value).Max();
}
else if (turn == 2)
{
greedyActionValue = actionValues.Select(e => e.Value).Min();
}
return actionValues.Where(e => e.Value == greedyActionValue).Select(e => e.Key);
}
검은 돌일 때는 여느때와 같이 보상이 최댓값, 흰 돌일 때는 최솟값인 행동을 반환한다.
결과적으로 현재 상태에 따른 행동들과 그에 대한 보상들이 있는 Q함수에서, 그리디를 이용해 현재의 최적해를 선택한다!
선생님께서 만든 프로그램! DP와 Q-Learning을 경쟁시킬 수 있다.
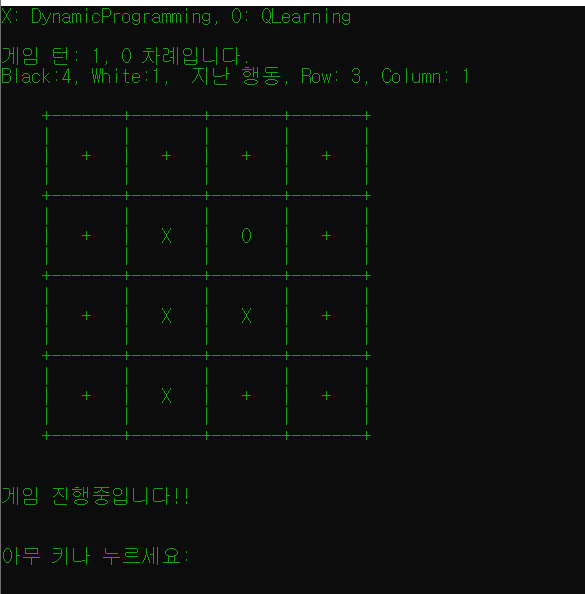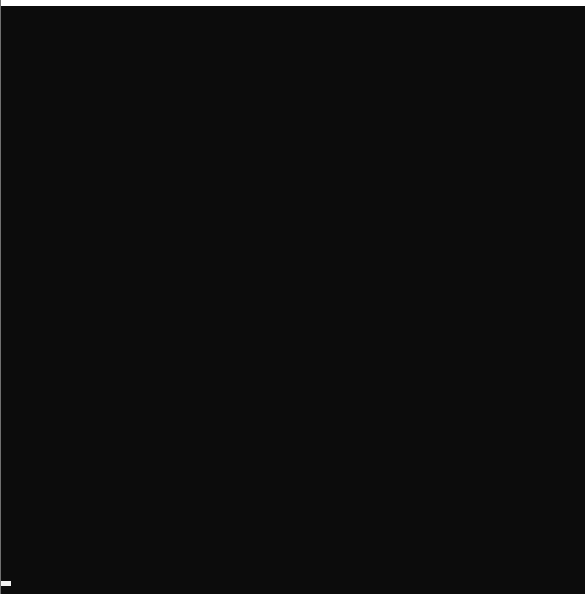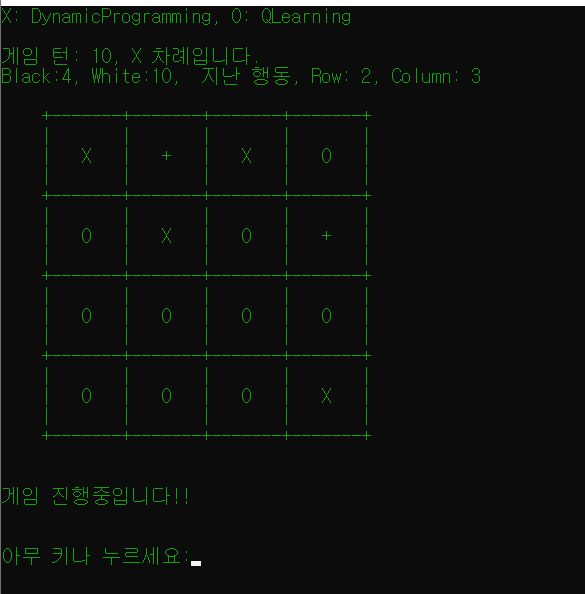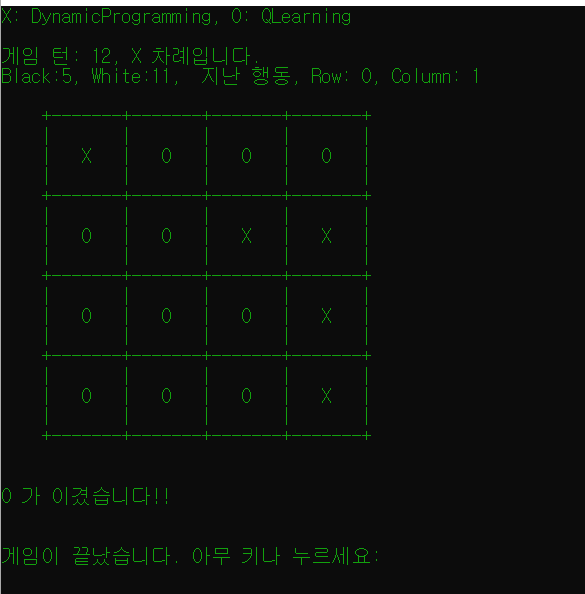
비록 4일이라는 짧은 시간이었지만, 좁은 우물 안을 탈출해 다른 학문의 깊이가 얼마나 깊은지 알게 되었던 시간이다. 다이렉트 X를 배울 때와 같은 감정이었다.
AI에 대해 개미만큼이라도, 가치 함수가 무엇인지, 상태, 행동, 보상이 어떤 걸 의미하는지 조금이나마 알게 되어 좋았다. 내가 몰랐던 다른 걸 접하며 배우고, 연구하고, 어려워하고 그것만으로도 가치가 있었던 동계 캠프!
잊어버리지 않게 자주 오자. 우물 안을 탈출하자!
깃허브에 전체 코드를 올렸다. 코드는 전부 선생님이 짜신 것!
GitHub - minyoung529/Winter_AI
Contribute to minyoung529/Winter_AI development by creating an account on GitHub.
github.com
'AI' 카테고리의 다른 글
| [AI][C#][오델로 AI] 2. DP로 오델로 AI를 만들자! (0) | 2023.01.14 |
|---|---|
| [AI][C#][오델로 AI] 1. 오델로 AI의 구조를 짜보자! (1) | 2023.01.14 |